我们提出了一系列单人/多人/人物运动的生成算法,能够根据一定的提示词生成相对应的动作序列。此外,我们还能够对于某个运动序列,生成相对应的动作序列,实现交互的效果。
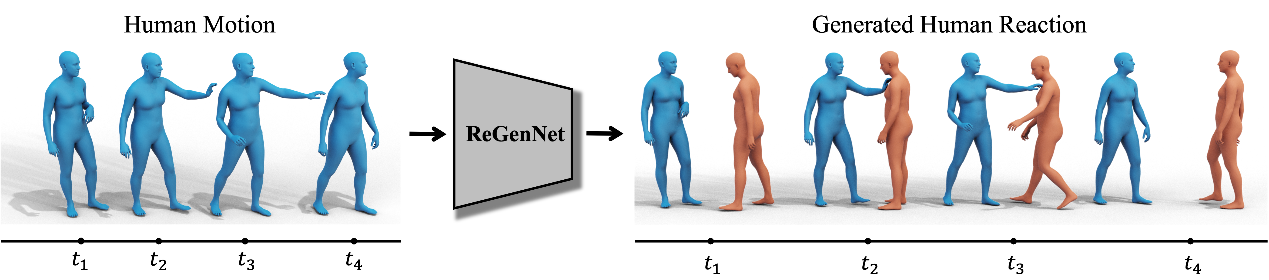
首先,我们全面分析了人与人交互的不对称、动态、同步和详细性质,并提出了第一个多设置人类动作反应综合基准,以根据给定的人类动作生成人类反应。 首先,我们建议注释 NTU120、InterHuman 和 Chi3D 数据集的交互序列的行动者-反应者顺序。 基于它们,提出了一种基于扩散的生成模型,具有名为 ReGenNet 的 Transformer 解码器架构以及基于显式距离的交互损失,以在线方式预测人类反应,其中反应器无法获得参与者的未来状态。 定量和定性结果表明,与基线相比,我们的方法可以生成即时且合理的人类反应,并且可以推广到看不见的演员动作和视角变化。
相关论文发表于世界顶级计算机视觉会议ICCV2023/CVPR2024中。